本研究基于中国知网(以下简称“知网”)丰富的学术资源,筛选出覆盖广泛学科领域的多类型学术文献,构建了一个具有专业性和多样性的高质量学术数据集AcaDS。采用Transformer架构训练了一个70亿参数规模的生成式学术大模型AcaLM-7B,并通过实验评测该模型在面向学术研究的6个核心应用场景中的性能,从而分析大规模高质量数据资源在构建专业大模型中的作用。
1 基础数据集与指令数据集构建
1.1 高质量数据集特性
在构建用于训练学术大模型的数据集时,高质量数据集的特性尤为重要。这些特性不仅关乎模型训练的效率和效果,更直接影响模型在下游任务中的性能表现。以下是从数量规模、数据质量、多样性、专业性和通用性等方面对高质量数据集特性的阐述。
首先,高质量数据集应具备一定的数量规模。这种规模不仅体现在数据量的多少,更在于数据是否能够全面覆盖下游领域的任务。数据集需要包含足够多的样本,以确保模型能够学习各领域的知识。
其次,数据质量是高质量数据集的核心要素。数据集的来源应是专业领域内被广泛认可的权威数据,以保证数据的可靠性。数据应经过进一步严格筛选和清洗,去除其中的噪声、重复和无关信息,以确保数据的准确性。
此外,数据的多样性也是高质量数据集的重要特性。多样性体现在数据的来源、类型及数据在各维度上的平衡。学术大模型通常是面向多任务的,数据集需要在满足覆盖多学科要求的同时,在各学科领域之间保持平衡,以避免模型在训练中出现偏倚或过度拟合的情况。
最后,数据的专业性和通用性也是高质量数据集的特性。专业性体现在数据集包含特定领域的专业基础和前沿技术。通用性则体现在数据集具备广泛的适用性,能够支持多种应用场景。专业性和通用性的结合有助于模型在特定领域内表现出色,同时也使其具备一定的跨领域应用能力。
1.2 基础数据集构建
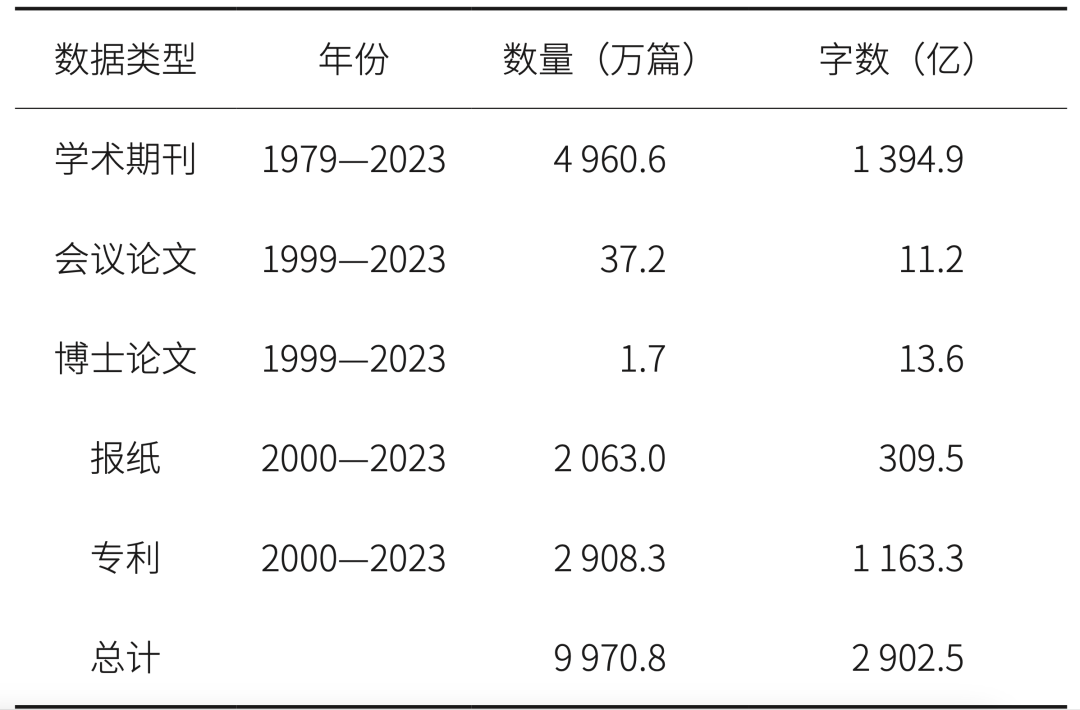
基于知网学术资源库,本研究收集了学术期刊、各类型论文、报纸、专利等多类型的学术文献,总计约2 902.5亿字文本数据,覆盖近亿篇文献,文本数据来源分布见表1。基于该文本数据进行严格的数据筛选和清洗,去除噪声和重复信息,保留高质量的数据样本,构建了1 316.45亿token的学术资源数据集AcaDS。
表1 文本数据来源分布
数据集AcaDS在数据分布上力求均匀,覆盖不同年份及广泛学科,以提供全面、深入的学术领域知识。AcaDS中不同科学领域数据的占比情况见图1。

图1 AcaDS中不同科学领域数据分布
AcaDS充分满足了高质量数据集在数量规模、数据质量、多样性等方面的要求。其权威的数据来源、严格的数据筛选和清洗过程,以及广泛覆盖不同学科领域的特点,使得AcaDS能够为学术大模型的训练提供坚实的数据基础。
1.3 数据预处理
在数据预处理阶段,首先进行数据去重操作以确保数据质量,旨在消除冗余和重复的数据,以提高数据集的纯净度和有效性。
接着进行分词处理,将学术文本切分为独立的词汇单元。由于学术文本的复杂性和专业性,分词算法需要特别考虑专业术语和缩写词,以确保准确捕捉文本中的关键信息。
最后,利用字节对编码(Byte Pair Encoding,BPE)算法将文本转换为固定长度的向量序列。BPE算法通过合并最常出现的子词来生成新的词汇单元,有效解决了未登录词(Out of Vocabulary,OOV)和稀有词的问题,为模型训练提供有效的数值化表示。这种表示方式不仅保留了文本中的关键信息,还降低了数据的维度和复杂性,从而提高了模型的训练效率和准确性。
1.4 指令数据集构建
本研究基于基础数据集AcaDS,根据学术论文的特点,抽取文章中的标题、摘要、大纲等关键数据,自动构建了包含2 700万条指令的大规模指令数据集AcaDSI。该数据集专注于6个核心学术领域的任务,包括摘要生成、文本续写、段落总结、大纲生成、开放问答和抽取问答。AcaDSI构建步骤见表2。
表2 指令数据集AcaDSI构建步骤

2 模型结构与训练策略
2.1 模型结构
AcaLM-7B模型是以开源模型LLaMa-7B为基础,针对学术领域的深度优化而构建的大型语言模型,参数规模70亿。其核心结构包含一个4 096维度的词向量嵌入层,通过堆叠32层的Transformer结构来捕捉文本中的深层语义信息,每一层采用32个注意力头数。此外,词表大小设置为55 000,以支持多语种、多符号的学术文本表达能力,窗口长度为8192,以支持对长文本的有效处理。
针对学术领域的优化方面,由于LLaMa-7B模型原始词典在适应学术文本上存在不足,因此本文利用学术领域数据,通过BPE算法生成了具备学术特色的词典,并采用词级粒度对文本进行分词处理。这不仅增强了模型对学术语义信息的理解,还提升了其处理长文本的能力。此外,本文引入DeepNorm方法替换原有归一化策略,有效缓解了模型参数更新问题,提高了训练稳定性,为模型未来扩展到更大规模(如百亿级别)奠定基础。
2.2 训练策略
AcaLM-7B模型的训练经历了两个阶段:首先,在1316.45亿token的预训练数据集AcaDS上进行训练,使模型掌握学术语言规律;然后,在2 700万条指令的指令数据集AcaDSI上进行微调,确保预训练后的模型更适应学术下游任务的具体应用场景。
训练硬件环境为GPU_Nvidia_ A800_640G_8GPU-Mods*4。
3 实验结果
3.1 评测任务与数据集
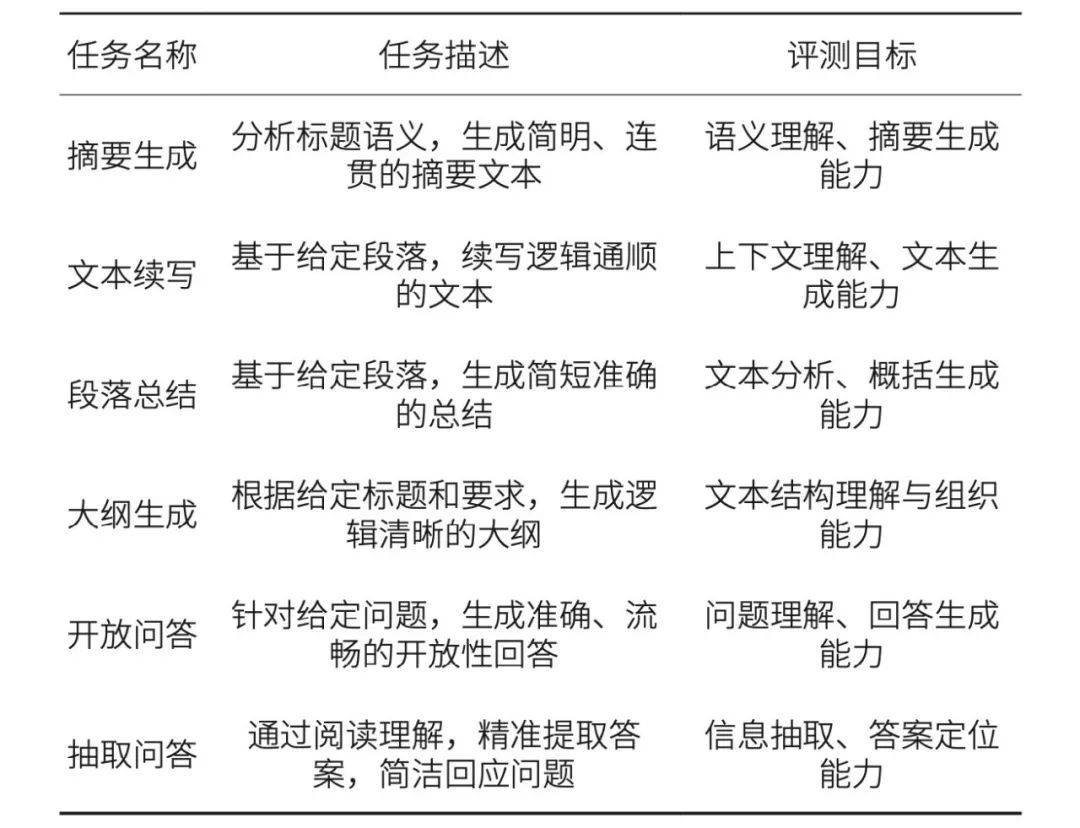
为检验AcaLM-7B模型的学术服务能力,本研究设计了6个学术领域常用的应用场景:摘要生成、文本续写、段落总结、大纲生成、开放问答和抽取问答,这些场景覆 盖了学术写作与研究的多个方面。任务描述与评测目标见表3。每项任务从指令数据集AcaDSI中随机抽取30个样本(不放回)作为测试数据,构成整个评测任务的数据集。
表3 模型评测任务描述与评测目录
3.2 评测模型
在评测中,依据数据来源、模型大小等综合因素,本文选取了华知大模型和ChatGLM-6B两款大模型,与AcaLM-7B共同参与评测。
华知大模型,是同方知网与华为公司联合研发的面向知识服务领域的大语言模型,参数规模约380亿。该模型以盘古38B模型为基础,使用知网部分专业学术资源进行增强训练,以提高其专业知识服务能力。
ChatGLM-6B,是目前10B以下参数中质量较好的开源通用大模型之一,它继承了GLM-3系列前代模型的优秀特性,支持多种复杂应用场景,具有出色的通用性能。
选择华知大模型参与评测,旨在探究大模型在结合专业资源训练后的性能表现。选择ChatGLM-6B参与评测,是由于其参数量与AcaLM-7B相近,在目前相近参数量的开源大模型中质量较好,进而可以对比其与仅依赖专业资源构建的AcaLM-7B在性能上的差异,从而探究不同构建方式对模型性能的影响机制。
3.3 人工评测
在人工评测环节,笔者邀请5名具备大模型评测经验的工作人员参与,通过多轮交叉评测确保结果的客观性。在每轮评测中,工作人员随机接收不同任务,并在任务轮换中完成对多个模型的评测,以减少主观偏见。评测采用排名积分制(5分制),根据模型表现进行排名并赋分。每轮任务完成后,计算平均得分作为本轮成绩,最终取多轮评测得分的均值,转化为百分制(乘以20)得出模型的最终评测得分。
最后,每个模型在6项评测任务中的平均得分为该模型服务学术任务的总积分。
3.4 结果分析
对AcaLM-7B、华知大模型、ChatGLM-6B这3个大模型的综合评测结果见表4,可视化效果图见图2。
表4 模型综合评测结果
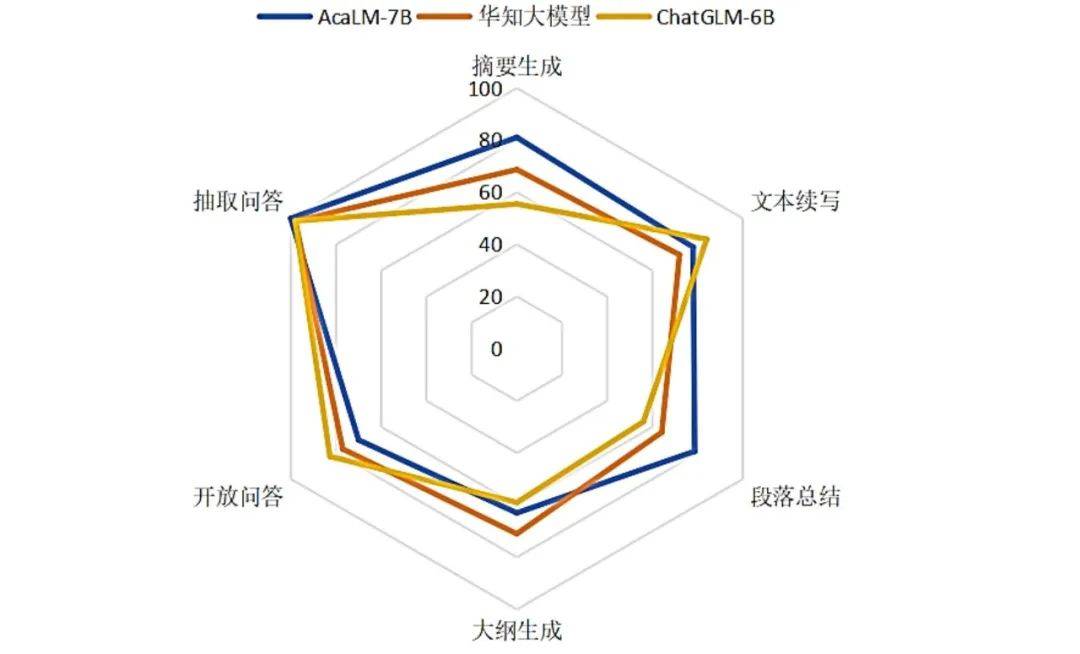
图2 模型综合评测结果可视化效果图
综合评测结果显示,AcaLM-7B的总积分排名第一,华知大模型紧随其后,ChatGLM-6B位列第三。此结果反映了3个大模型对下游学术任务的服务能力是不同的,AcaLM-7B整体效果最好。
3.4.1 AcaLM-7B
具体来看,AcaLM-7B在摘要生成、段落总结和抽取问答3个任务中均排名第一,同时在文本续写和大纲生成任务中排名第二,从而以最高总积分在综合评测中脱颖而出。这充分说明AcaLM-7B在理解和处理学术文本信息、提取关键学术内容方面具有强大能力。摘要生成任务、段落总结任务评测中实例分别见表5、表6。
表5 摘要生成任务评测实例
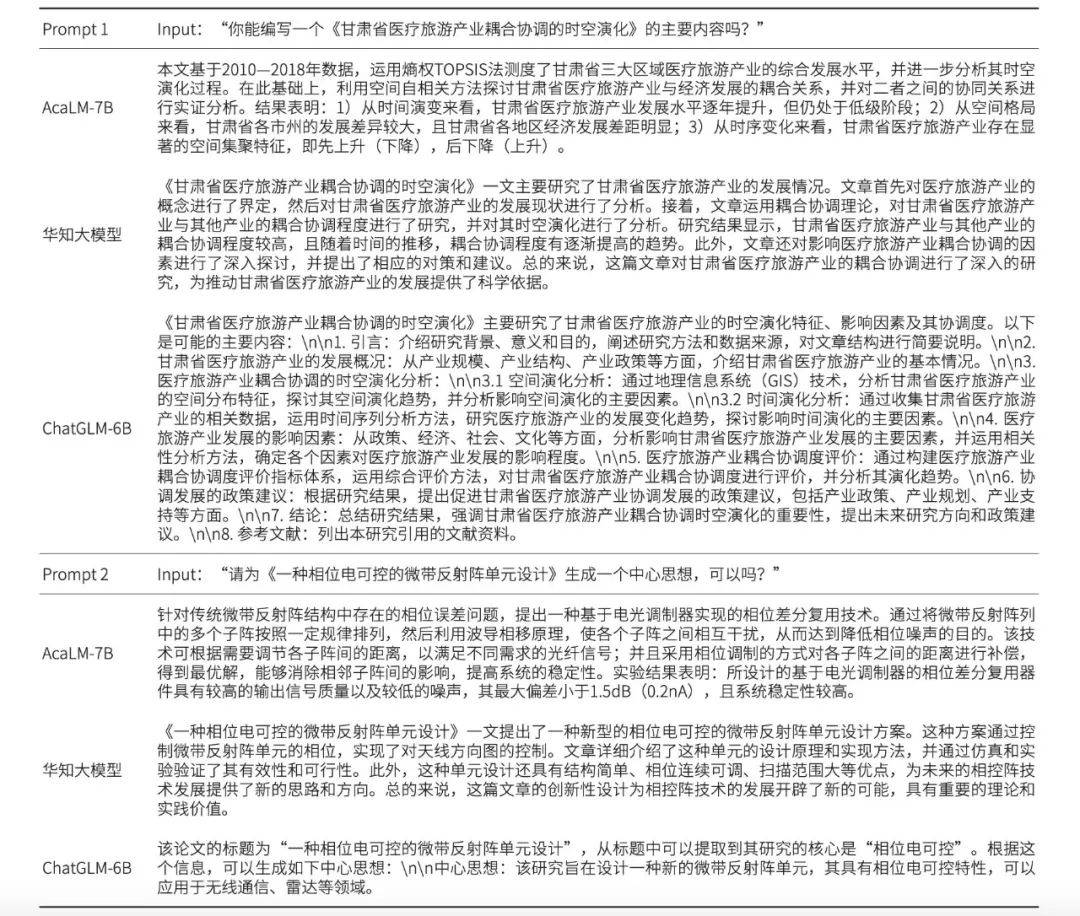
表 6 段落总结任务评测实例

如表5所示,从摘要生成任务实例中可以看出,AcaLM-7B能够准确捕捉论文的核心内容,并生成精炼且连贯的摘要文本。它成功地涵盖了研究目的、方法、结果及结论等关键信息,提供了对论文全面且准确的理解。相比之下,华知大模型与ChatGLM-6B在摘要生成方面稍显不足,存在信息遗漏或表达不够准确的问题。
实例1(Prompt 1)中,AcaLM-7B精准捕捉了医疗旅游产业的发展概况、时空演化特征及影响因素等多个关键信息,并生成了具有高度概括性和可读性的摘要;华知大模型虽然对医疗旅游产业的概念、发展现状及耦合协调程度进行了分析,但在表达上不够准确,部分信息未能完全捕捉;ChatGLM-6B虽然提供了较为详细的内容框架,但在具体信息的呈现上略显笼统,未能充分展现学术论文的精髓。
实例2(Prompt 2)中,AcaLM-7B不仅准确提炼了研究的核心内容,还对其设计原理、实现方法及实验验证结果进行了详尽而深入的分析,生成的摘要逻辑清晰、条理分明,能够充分展现论文的创新点和学术价值;华知大模型虽然也提到了微带反射阵单元的相位电可控设计,但并未深入探讨其设计原理和实现方法,只是简要概述了其优点和应用方向;ChatGLM-6B则更侧重于从标题中提取关键信息,生成了较为简洁的中心思想,缺乏对论文内容的深入理解和阐述。
通过分析,AcaLM-7B在摘要生成任务上的优势主要得益于其训练过程中所使用的专业优质资源,这些资源为模型提供了丰富的学术领域知识,使其能够准确地理解并生成学术文本的摘要。
如表6所示,从段落总结任务实例中可以看出,AcaLM-7B对信息的捕捉精准且概括能力突出,华知大模型和ChatGLM-6B的总结内容都稍显冗长,在简洁性和概括性方面有所欠缺。
实例1(Prompt 1)中,对于养老保险关系转移规定的描述,AcaLM-7B的总结既准确又简洁,直接点明了跨省转移养老保险关系的一般规定,充分体现了其高效的信息处理能力;华知大模型虽然准确地提到了转移的规定,但表述略显冗长,超过了字数限制;ChatGLM-6B则较为详细地描述了转移的各种情况,包括省内外的不同处理方式,但同样在字数控制上稍显不足。
实例2(Prompt 2)中,AcaLM-7B准确地抓住了作文立意与学生个性发展之间的关系,并用简洁的语言进行了概括,既符合字数要求又体现了文本的核心要义;华知大模型较为全面地概括了作文教学中立意的重要性及如何通过提炼主题和渗透学生个性来培养学生写出有新意的作文,但在字数控制上仍稍显不足;ChatGLM-6B则详细描述了新课改的要求及如何通过具体例子来体现好的立意,但同样在简洁性上有所欠缺。
通过分析,AcaLM-7B在段落总结任务中的出色表现,同样得益于其训练过程中的专业优质资源及模型架构优化。这些因素共同作用,使得AcaLM-7B能够更准确地理解段落内容并生成简洁明了的总结。
3.4.2 华知大模型
华知大模型在大纲生成任务中排名第一,同时在摘要生成、段落总结、开放问答及抽取问答4项任务中位列第二,总积分排名第二。大纲生成任务评测中的实例见表7。
表7 大纲生成任务评测实例

从大纲生成任务实例中可以看出,华知大模型能够准确布局论文的各个部分和章节,并生成清晰的大纲框架,从引言到结论,每个部分都进行了详细的规划和说明。相比之下,AcaLM-7B与ChatGLM-6B在大纲生成时存在结构不清晰或内容不完整的问题。
华知大模型的出色性能主要得益于两方面:一是华知大模型以华为的38B盘古大模型为基座,基于知网的学术资源进行二次训练,习得了专业领域的知识表示,有助于解决下游专业任务;二是华知大模型的参数量比AcaLM-7B大5倍,因而知识表示更专业、学习能力更强。
3.4.3 ChatGLM-6B
ChatGLM-6B在文本续写和开放问答2个任务中排名第一,表现出该模型在理解和生成自然流畅文本、开放问答场景方面的强大能力。特别是在开放问答任务中,ChatGLM-6B的得分远高于其他2个模型,进一步凸显其在问答领域的优势。开放问答任务中的评测实例见表8。
表8 开放问答任务评测实例

开放问答任务实例中可以看出,ChatGLM-6B能够准确理解问题的背景和需求,并提取相关信息进行回答。相比之下,AcaLM-7B与华知大模型在回答时存在信息不足或回答不够准确的问题。
ChatGLM-6B在开放问答任务中的出色表现,主要由于模型在训练阶段对通用问答数据的深度挖掘及模型架构针对问答任务的专项优化。这些因素共同促使ChatGLM-6B能够精准理解问题,并从知识库中提取相关信息,给出准确回答。
然而,ChatGLM-6B在其他评测任务中的表现相对较弱。这源于该模型主要基于公开、通用的数据集进行训练,缺乏专业文献资源的支撑。因此,在应对专业领域的开放问题时,ChatGLM-6B表现出一定的局限性。
通过对各个评测任务的结果分析,可以发现大模型的性能不仅与其参数规模紧密相关,训练资源的多样性、质量、专业性及通用性也同样关键。特别是,大规模高质量专业数据资源对于大模型的性能提升具有显著影响。华知大模型因庞大的参数量在特定任务中表现出色,ChatGLM-6B则凸显通用知识的重要性,这也为提升AcaLM-6B整体性能提供了两个方向:一是通过扩大模型规模来增强其表示与学习能力;二是加入更多通用资源,以提高模型在特定领域与通用场景下的整体性能。实验结果论证了大规模高质量数据在模型构建与优化中占据的核心地位。研究发现不应仅关注模型参数的规模,更要深入探索如何有效整合和利用这些高质量数据,以推动大模型技术的发展和性能的提升。
4 结语
本研究深入探究了大规模高质量数据集在构建专业大模型中的核心作用。基于知网大规模的专业文献,本研究构建了包含1 316.45亿token的高质量学术资源数据集AcaDS,根据学术文献特点,自动合成了2700万条指令的微调数据集AcaDSI,训练了70亿参数量的生成式学术大模型 AcaLM-7B。针对学术研究常用的应用场景,本研究设计了6个下游评测任务,并对AcaLM-7B、华知大模型、ChatGLM-6B 这3个大模型进行了综合评测。
实验结果显示,AcaLM-7B在面向学术研究的6个应用场景中获得总积分第一,并在摘要生成、段落总结和抽取问答3个任务中均排名第一。这一结果充分验证了大规模高质量数据资源在构建专业大模型中的关键作用。AcaLM-7B通过利用知网大规模的专业文献数据,习得了丰富的专业领域知识表示,从而在处理学术任务时表现出色。
与此同时,华知大模型和ChatGLM-6B也展现了各自的优势。华知大模型基于华为的38B盘古大模型,通过二次训练增加了学术资源,其庞大的参数量(比AcaLM-7B大5倍)使得其在大纲生成任务中表现突出。ChatGLM-6B则在文本续写和开放问答任务中取得了显著成绩,特别是在开放问答任务中,其得分远高于其他2个模型,凸显了其在问答领域的优势。
通过对比分析,本研究揭示了不同类型大模型在不同任务中的性能差异与潜在优势。这一发现不仅为构建更加全面、均衡的高性能大模型提供了重要参考,也为未来研究指明了方向。未来研究可进一步关注如何结合专业资源与通用知识,构建更加全面、均衡的高性能大模型,满足多样化实际应用场景的需求。
未来的研究将不再局限于单一的数据集或模型,而是会进一步探索多源数据的融合策略,构建出更加全面、均衡的大模型。首先,进一步探索多源数据的融合技术,通过整合来自不同领域的数据,构建出更加丰富、均衡的数据集,以支持大模型在更广泛场景下的应用。其次,关注数据的动态更新和扩展。随着学术领域知识的不断发展和新研究成果的涌现,数据集需要不断更新以反映最新的学术动态。此外,研究数 据集的标签质量和多样性也非常重要,通过提高标签的准确性和丰富性,进一步提升大模型在各类学术任务中的性能。最后,研究将致力于构建跨领域、跨语言的数据集,支持大模型在全球化、多语言环境下的应用。这些研究方向为构建更高质量、更具实际应用价值的数据集提供有力支撑,并进一步推动专业大模型的发展。
本文摘自《数字出版研究》2024年第3期 薛德军,师庆辉,毕琰虹,芦筱菲,陈婧,王旭,王海山,耿崇,吴晨《数据引擎驱动的学术出版大模型——实测检验大规模高质量数据在构建高性能模型中的核心地位》,注释及参考文献从略。阅读全文或学术引用请参见原文。
国际标准连续出版物号:ISSN 2097-1869
国内统一连续出版物号:CN 10-1854/G2
邮发代号: 80-913 季刊 定价:40元/期
电话: 010-6488 3888
邮箱:editor@dpresearch.cn
投稿网址:https://szcb.cbpt.cnki.net 返回搜狐,查看更多
责任编辑:
平台声明:该文观点仅代表作者本人,搜狐号系信息发布平台,搜狐仅提供信息存储空间服务。
阅读 ()